主从复制
🚧注意:非终稿,不定期更新。
“What I cannot create, I do not understand.” – Richard Feynman
所谓分布式系统,就是一群计算机通过网络协调完成某一串连贯的任务,是一个包含了各种工程实践及理论的庞杂话题。
需要分布式系统的场景主要有两个:
某些系统同时存在以上两种需求,而使用分布式进行容错包含了分布式系统设计的很多难点和精髓,只是资料阅读很难让人体会到其中的乐趣和困难。
所以笔者在业余时间,通过将一个单机的leveldb实现扩展为分布式容错实现, 检验、加深了自己对分布式系统实现的理解,整理出本篇文档,给同样对相关主题感兴趣的读者提供思路。
项目源码及构建、运行方式请参看:项目主页。
代码里的leveldb功能采用了现有的一个java版本的单机实现, 在本项目中,在其基础上实现了基于redis协议的网络接口及分布式容错设计。
容错经常和灾备、高可用混淆,三者可以通过例子简单的区分:
可以看出,容错实现的难度最大,我们先思考相对简单的灾备实现,比较其与容错设计的不同之处。
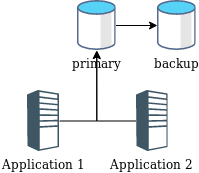
对于需要依赖持久化保存状态、实现功能的系统(如本文的leveldb key-value服务、数据库等),最常见的灾备方式便是主从复制:
一台机器提供服务,其他机器通过网络对这台机器的数据在本地进行备份。如图:
主从复制
主从复制分为同步方式和异步方式,同步方式是指请求备份成功后返回给客户端结果,异步是指先返回结果给客户端再进行同步。
如果主节点所在硬件被损坏,导致持久化的数据无法恢复,可以使用从节点的备份数据进行恢复。
但是无论同步备份还是异步备份,都无法确保数据无丢失,因为主节点的任何备份操作都有可能因宕机无法通知到从节点。
以上实现的高可用性一般,因为只有一台从节点服务,如果该从节点宕机,为了降低数据丢失的风险, 我们可能需要暂停主节点,直到从服务恢复或替换成新的从节点。
可以提供多台从节点提高可用性,只要有一台从节点可用,主节点就可以不用暂停服务。 如图:
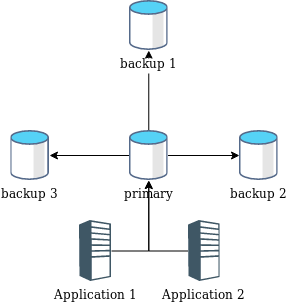
高可用主从复制
但这会导致一个新问题,某些节点和网络链路可能反复异常然后又恢复,导致从节点之间的备份数据相互不一致,需要额外的工作使各个从节点数据最终一致。
除了这个问题,主从复制方案还存在单点故障问题,只要主节点进程失败,整个服务都不可用,无法满足我们的高可用需求。
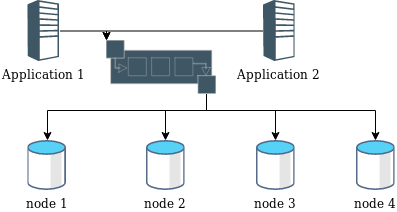
为了容错,我们可提供多个服务进程的副本,客户端连接其中一个节点发起请求,收到请求的节点使用某种格式的记录该请求,并同步给各个节点进行执行。
当某个节点宕机或网络不可达时,另一个节点可以继续为客户提供服务,宕机节点恢复后, 它可以从其他节点获取宕机后的日志进行回放,赶上其他节点的状态。
但是,网络分区会使得不同客户端可能会使用不同节点进行读写请求,如:
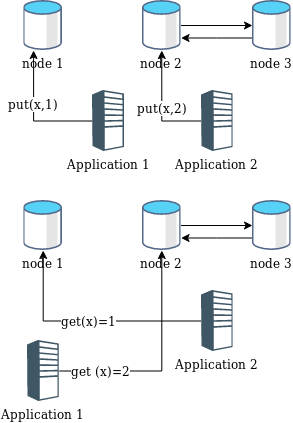
网络分区
某个时候开始,节点1与其他节点无法通信,分为两个网络,以key-value服务操作为例, 应用1先在节点1的网络分区,应用2在节点2的网络分区,并发执行写操作, 接着,应用1和2的分区同时进行了切换,对相同key进行读操作,就出现以下的现象:
客户端A在节点1执行:set(x,1)
客户端B在节点2执行:set(x,2)
客户端A在节点2执行:get(x),结果为2
客户端B在节点1执行:get(x),结果为1以上结果违背了顺序一致性,A的get(x)结果为2说明B的set(x,2)已执行,B的get(x)返回值应为2,如果B的某次计算依赖A的get(x),那么B的get(x)为1将可能导致应用bug, 也会导致使用者的困惑。
比如在拍卖系统中,如果set操作代表的是某个用户的出价,这两个读写结果与用户预期是不符的,用户加价成功后,在一个客户端看到结果为2,在另一个客户端看到为1。
以上现象本质是各个节点进程对同一个变量发生了写冲突,如何在发生写冲突后立刻发现并解决冲突呢?
一种方案是一次写操作需写入w个节点,读操作读取r个节点,保证r+w>n(系统所有节点的个数),就一定能发现冲突。如图:
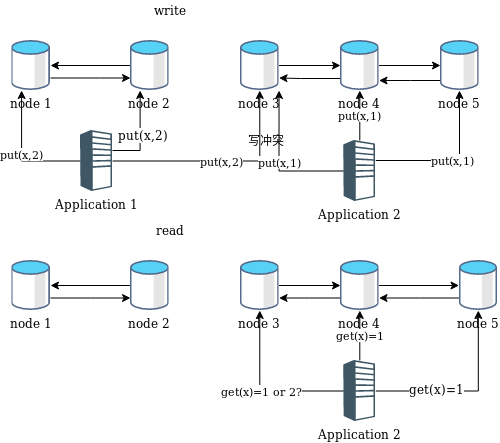
r=3,w=3,n=5
上图应用2在节点3的读取操作便发现了冲突,客户端需要某种策略确定保留一个版本。
一种常见思路是更新时带上该数据更新时间,服务端使用最新版本,但是在分布式系统里,时钟是不可靠的,每台机器的时钟不可能完全同步,就连做到接近的代价都很大。
举个例子,假设x此时为0,客户端A请求更新x为1,按照上面的算法,该请求在编号1,2,3的节点执行:
set(x,1)接着客户端B在3,4,5节点执行:
set(x,2)接着客户端A又从节点1,2,4执行get(x),假如由于时钟误差,1,2节点的时钟比4节点快(比如300ms), 导致节点1,2的时间戳版本比节点4的时间戳版本更新,结果返回1。
这就导致客户请求的set(x,1),set(x,2),get(x)三步操作的结果为1,这当然与预期不符。
更糟糕的是,每个机器的时钟有可能时快时慢,计算结果更加不可预测,在分布式系统中, 逻辑时间是一种解决该时钟问题的方法。
除此之外,如果某个客户端应用无法连接w个节点和r个节点,则服务对该客户端不可用, 如果要提高可用性,可以在该客户端所在网络分区没有w个节点时,新建全新的节点满足要求,但这将破坏系统的一致性。
亚马逊DynamoDB便同时采用逻辑时钟及发生故障时新建节点的方案,尽可能满足正确性和高可用,尽管可能会在网络分区时发生以上举例的现象,但对要求不严格的场景, 如购物车,也够用了。
虽然可以通过逻辑时间标记数据版本解决一致性问题,但是对于复杂应用,如分布式数据库的SQL操作,逻辑时间解决起来是很复杂的。
所有分布式系统,都存在着这种正确性和可用性之间的权衡, 其中一种分布式系统正确性的衡量标准就是一致性模型。
容错设计便是即满足正确性(使用一致性衡量)又满足极高的可用性
一致性模型有强弱之分,一致性越强,对应用程序或程序员越友好,但是实现难度更大,性能更差;反之,一致性越弱,一般实现更简单,性能更好,但对应用者更加不友好、更不可预测。
作为挑战,我们要实现的leveldb服务要满足顺序一致性:
the result of any execution is the same as if the operations of all the processors were executed in some sequential order, and the operations of each individual processor appear in this sequence in the order specified by its program. - - Lamport
比如,客户端1执行:
set(x,1),set(y,2),get(x),get(y)客户端2执行:
set(z,3),set(y,3),get(x),get(z)在服务器上可能的一种结果是:
set(x,1),set(z,3),set(y,2),set(y,3),get(x),get(y),get(x),get(z)以下结果是顺序一致性不允许的:
set(x,1),set(y,2),set(y,3),set(z,3),get(x),get(z),get(x),get(y)因为set(z,3)发生set(y,3)后面,这不是客户端2程序指定的顺序。
不同客户端看到不同的总体执行顺序也是不允许的。
为了满足顺序一致性,一种直观的解法是选举一个Leader接收请求,只有leader接收请求,并按顺序发送到其他进程节点,当前不是Leader的节点拒绝客户端请求, 并将客户端重定向到leader提供服务。
但是,如何保证每个客户端的Leader是一样的呢?如果在请求过程中,Leader发生了变化呢?
可以看到,要满足顺序一致性,Leader更新过程本身也是操作顺序的一部分,和其他业务请求面对的问题一样。如下所示:
set(x,1),leader(server 1),put(x,2),leader(server 2)这个问题的本质是,所有的进程相关的状态变更,在所有节点上的顺序必须保持一致,且每个状态变更的结果对进程影响一致。
如果将每个节点进程看做一个单独的状态机,那么在前面输入都相同的情况下,每个状态机对当前输入的输出结果一定是一样的。
这便是复制状态机的思想:
复制状态机
如果对每个状态变更进行递增编号,只要保证每个节点对相同编号的变更内容一致,即可实现复制状态机,这种做法称为全序广播或原子广播。 全序广播可以保证顺序一致性。
这就把问题变成了一个典型的分布式共识问题:
异步系统中,多个进程对某一个提案的内容达成一致的过程,就是共识。
协商每个编号操作内容的过程,就是一次分布式共识达成过程,因此全序广播问题又等价为共识问题。
在可能存在网络分区的异步网络中,常见的共识算法有Paxos和raft,我们使用Paxos共识算法。
Paxos算法的推导过程就是一个为了得到结果,不断对条件进行约束的过程。
首先,某个节点作为发起者(proposer),对其他节点发起提案,接收者需要满足约束P1:
P1:一个 acceptor 必须接受(accept)第一次收到的提案。
显然,违反P1的系统,不会通过任何提案被通过。
但如果网络分裂为A和B两个网络,A和B不能互通,一个提案在A得到批准,另一个提案在B网络得到批准,则会出现提案不一致的情况。 解决方案是只批准获得超过一半(大多数)接收者同意的提案。
但是A和B网络可能有重叠,此时某些节点可能会收到两个或两个以上的提案,这些节点必须能够接受这些两个及以上的提案,因为按照约束P1, 这些提案可能是其他节点的第一个提案,已经被接受了。
为了区分提案,需要为提案分配编号,比如发起节点的本地序列号+ip地址。这里不要混淆提案的编号和复制状态机输入的编号, 状态机每个编号(依次递增)的输入内容对应一次共识过程,该共识过程可能存在多个编号(只需保证单调)的提案。
既然接收者需接收多个提案,这就引出约束P2:
P2:一旦一个具有 value v 的提案被批准(chosen),那么被批准(chosen)的更高编号的提案必须具有 value v。
提案被批准,表示至少被一个接收者接受过。所以加强P2,得到约束P2a:
一旦某个提案值v获得批准,任何接收者接收的更高编号的提案值也是v。
因为通信是异步的,一个从休眠或故障恢复的节点,给某个尚未收到任何提案的节点,提交一个更高编号的不同提案v1,按照约束P1,该节点必须接收该提案, 这就违背了约束P2a,所以,与其约束接收者,约束提交者更加方便,对P2a加强约束,得到约束P2b:
一旦某个提案值v获得批准,任何发起者发起的更高编号的提案值必须是v。
我们来证明P2b如何保证P2。
使用归纳法,假设编号为m(m < n)的提案被选中,且m到n-1的提案值都为v,那么存在一个大多数接收者的集合C接收了m提案,这意味着:
C中每个接收者都批准了m到n-1其中一个提案,m到n-1的每个被批准的提案其值都是v。
因为任何大多数接收者集合S,和C至少有一个公共接收者,编号为n的提案w被批准,那么只有两种情况:
- 存在一个包含大多数接收者的集合S,从未接受过小于n的提案。
- w和S中所有已接受的、编号小于n的最大编号提案值相同,即值为v。因为公共接收者需要批准相同的提案值。
这个证明看起来很多余,但是请注意,编号m到n的提案不是按编号先后顺序发起的,这些提案的发起顺序是没有保证的。
编号为n提案的发起者需要知道所有已接受提案中小于n的最大编号提案的值(如果有)。知道已接受的提案是值很简单的,预测未来很难办, 比如:编号为n的提案值,如何知道尚未收到的n-1编号提案的值呢。
与其预测未来,不如让接受者在之后拒绝所有小于n的提案。
由此强化约束P1,得到P1a:
接收者拒绝接受编号比当前已知最大编号n更小的提案。
得到Paxos算法过程如下:
我们对每个客户端请求不断使用以上算法,即可对每个编号的操作内容达成共识。这当然会导致某些客户提交的请求失败,但是可以通过客户端重试解决。
Paxos还存在一些优化技巧,减少通信次数,这里不实现,具体可参考相关资料。
提供服务的第一步是接受、解析客户端通过网络发送的命令请求,使用JAVA NIO处理。
首先打开socket接收客户连接,在连接成功的channel上挂载一个响应redis请求的handler——RespReadHandler。 使用RespDecoder类对异步到来的字节报文进行解码,RespReadHandler使用其get方法,判断请求是否解析完成。
解码完成后,使用KeyValueEngine进行真正的键值读写处理,此处先不考虑KeyValueEngine的实现细节。
执行完客户端命令后,ReadHandler新建一个RespWriteHandler将结果返回给客户端, 接着重新挂载一个RespReadHandler进行下一个请求处理。
重新生成RespWriterHandler和RespReadHandler是为了方便进行GC,当然可以手工管理各种buffer的回收和重利用,这里不做详细设计了。
因为保存的对象都比较小,KeyValueEngine并没有使用InputStream之类的模式进一步提升异步性能。
RespDecoder是redis的RESP协议解码器, RESP一共有以下几种数据类型:
除了ARRAY可以包含其他类型和ARRAY本身,处理稍稍麻烦外,其他类型都容易解析。
使用JAVA标准库中ByteBuffer类直接解析协议是比较困难的,不能等到报文读取完成后,才开始解析,因为错误格式的报文可能导致读取一直无法完成。
另外,报文处理往往需要"回溯"操作,从之前某个位置重新开始解析。使用ByteBuffer的flip和rewind、reset太底层,抽象层次不够。
所以通过实现自己的ByteBuf进行报文解析,主要提供了独立的读写index,方便回溯和读写操作分离。 底层使用byte[]保存数据,也可以使用direct allocate的ByteBuffer提升性能,但是ByteBuf的生命周期短,数据量较小,无法体现其优势,byte[]在这里满足要求了。
KeyValueEngine收到请求后,不会立即执行, 而是交给ReplicateStateMachine生成一个新的状态机输入, 并委托其对该输入所在编号的操作达成共识,共识达成后,ReplicateStateMachine回调KeyValueEngine接口执行,返回结果。
如果达成的共识内容不是提交的内容,返回客户端错误,客户端可以决定重试或报错。 详情见ReplicateStateMachine的apply方法。
这里需要注意,每个客户端的请求需要分配独立的id,以区分相同内容的客户请求,假如实现命令append,为key对应的value追加内容,两个相同的"append x y"请求如不加id会达成一次共识,但实际只执行了一次, value只追加了一个y。这与客户预期不一致,导致bug。解决方法是为待共识内容增加一个uuid:
public Input newState(byte[] content) throws DuplicateKeyException {
return Input.builder().id(next()).uuid(uuid()).content(content).build();
}ReplicateStateMachine可以并发进行多个Paxos共识实例,每个实例递增分配一个编号,所有RSM实例都按照编号顺序,使用后台线程顺序执行所有编号的共识结果。
顺序执行意味着KeyValueEngine无法并发处理已完成共识的各个请求,如果需要提高并发性,需要保证不同机器并发执行的结果一样,这是比较困难的, 需要完善各种锁机制和并发控制,这里不做实现。
进程可能在KeyValueEngine执行数据操作命令过程中失败,或者执行完成,但在返回ReplicateStateMachine前失败,服务需要在恢复时恢复之前的正确状态。 一般需要采用写前日志技术保证可恢复,我们的RSM使用leveldb保存各种内部状态,leveldb本身实现了写前日志。
比如保存当前执行的编号:
private void writeRedoLog(int id) throws IOException, ExecutionException {
persistence.put(RSM_DONE_REDO, ByteBuffer.allocate(4).putInt(id).array());
}执行成功后,删掉该记录:
private void removeRedoLog() throws IOException, ExecutionException {
persistence.del(RSM_DONE_REDO);
}如果进程中途宕机,进程重启时,会检查相关日志,恢复相关执行现场:
public void start(StateTransfer transfer, Executor executor)
throws IOException, ExecutionException {
this.stateTransfer = transfer;
Integer d = getRedoLog();
if (d != null) {
this.done.set(d);
} else {
byte[] bytes = persistence.get(RSM_DONE);
if (bytes == null) {
this.done.set(-1);
} else {
this.done.set(ByteBuffer.wrap(bytes).getInt());
}
}
sequence.set(this.done.get() + 1);
// ... 恢复完成,启动RSM线程服务
}leveldb的SET、DEL、GET都是幂等的,重复执行没有问题,只要保证不漏掉命令就行。具体可查看start方法和apply方法。
ReplicateStateMachine并发提交共识请求给共识服务Coordinator。 Coordinator可以由各种共识算法实现,这里是Paxos实现。提供Coordinator接口是为了方便测试mock和扩展。
完成一次共识过程的Paxos伪代码如下:
--- Paxos Proposer ---
1 proposer(v):
2 while not decided:
2 choose n, unique and higher than any n seen so far
3 send prepare(n) to all servers including self
4 if prepare_ok(n, na, va) from majority:
5 v' = va with highest na; choose own v otherwise
6 send accept(n, v') to all
7 if accept_ok(n) from majority:
8 send decided(v') to all
--- Paxos Acceptor ---
9 acceptor state on each node (persistent):
10 np --- highest prepare seen
11 na, va --- highest accept seen
12 acceptor's prepare(n) handler:
13 if n > np
14 np = n
15 reply prepare_ok(n, na, va)
16 else
17 reply prepare_reject
18 acceptor's accept(n, v) handler:
19 if n >= np
20 np = n
21 na = n
22 va = v
23 reply accept_ok(n)
24 else
25 reply accept_rejectPaxos算法有优化版本,如multi-paxos可以减少一次请求,我们使用原始算法。
Paxos类作为Paxos服务的门面类,提供共识请求、共识结果查询等功能入口。 他为每个共识实例创建相应的发起者(proposer),同时为本节点和其他节点的发起者创建、管理对应的接收者(acceptor)。
Proposer为算法发起者实现, LocalAcceptor为算法接收者实现。
各个实例的提案请求可能来自其他节点,所以需要提供一个网络服务PaxosServer, 通过参数中的编号区分不同共识过程实例,转发给不同实例的本地接收者处理,然后返回响应。
配套的,提供SyncProxyAcceptor作为远端接收者的本地网络代理, 请求各个PaxosServer完成提案过程。
这些Proxy及Server相当于简单实现了一个RPC框架。
InetPeerAcceptors为SyncProxyAceptor的创建工厂, 使用一个简单的连接池为SyncProxyAcceptor提供nio channel实例。
接口参数使用RESP协议编解码,SyncProxyAcceptor使用同步网络API,简化使用逻辑。 如prepare方法的代理:
Prepare delegatePrepare(int round, String n) throws IOException {
synchronized (channel) {
ByteBuffer request = codec.encodePrepare(round, n);
while (request.hasRemaining()) {
channel.write(request);
}
return codec.decodePrepare(channel, n);
}
}Paxos伪代码很简单,但是在进程可能异常退出的情况下,是不够完备的。进程被杀死、断电都会导致正在共识协商的进程退出,并在恢复后,出现错误的结果。
举个例子,多数派为某个编号的共识实例通过了一个提案,但是在decide阶段,多数派全部异常退出,只有多数派以外的节点处理了提案结果。 稍后这些多数派又恢复,之前的信息已经丢失,此时又收到同一个共识实例编号的另一个提案,此提案被通过,和未异常退出的节点接受的提案不一致。
所以,在prepare和accept阶段,都需要持久化Acceptor的状态,同样在这里使用leveldb接口即可,实例化Acceptor时,先尝试恢复已持久化的状态。 并通过一个定期的心跳请求,学习其他节点的共识结果,快速赶上进度,见heartbeat方法:
private void heartbeat() throws IOException, ExecutionException {
int begin = done() + 1;
Preconditions.checkState(begin >= 0);
int end = coordinator.max();
while (begin <= end) {
coordinator.learn(begin);
begin++;
}
}LocalAcceptor的prepare方法也需要防止中途宕机, 防止重启时又投票给不同的共识内容。
@Override
public synchronized Prepare prepare(String n) throws Exception {
if (np == null || n.compareTo(np) > 0) {
np = n;
persistence(); // 保存状态
return Prepare.ok(n, na, va);
}
return Prepare.reject(n);
}Paxos类保存和恢复acceptor的方法分别如下:
void persistenceAcceptor(int round, LocalAcceptor acceptor) throws IOException, ExecutionException {
if (Strings.isNullOrEmpty(acceptor.getNp())) {
return;
}
persistence.put((round + "np").getBytes(), acceptor.getNp().getBytes());
if (!Strings.isNullOrEmpty(acceptor.getNa())) {
persistence.put((round + "na").getBytes(), acceptor.getNa().getBytes());
}
if (acceptor.getVa() != null) {
persistence.put((round + "va").getBytes(), acceptor.getVa());
}
}
Optional<LocalAcceptor> regainAcceptor(int round) throws IOException, ExecutionException {
byte[] np = persistence.get((round + "np").getBytes());
if (np == null) {
return Optional.empty();
}
byte[] na = persistence.get((round + "na").getBytes());
byte[] va = persistence.get((round + "va").getBytes());
String nps = new String(np);
String nas = na == null ? null : new String(na);
return Optional.of(new LocalAcceptorWithPersistence(round, nps, nas, va));
}输入一直在增长,需要删除共识服务中已经处理完成的输入,见RSM的forget方法:
private void forget() throws IOException, ExecutionException {
// 一次处理一百条
if (threshold.incrementAndGet() > 100) {
threshold.set(0);
coordinator.forget(done());
}
}根据FLP不可能原理:
任何分布式共识算法,只要有一个进程宕机,剩余的进程存在永远无法达成共识的可能性。
对于Paxos算法,很容易找到无法达成共识的情况,比如不同proposer的accept请求,每次都因其他proposer产生的更高prepare编号而被大部分acceptor拒绝。
解决办法是在可能冲突时,引入随机等待,降低这种可能性,并在重试达到最大次数时,失败退出。如:
if (!decided) {
retryCount++;
try {
Thread.sleep(Math.abs(random.nextInt()) % 300);
} catch (InterruptedException e) {
logger.error("Failed in propose.", e);
return null;
}
if (retryCount >= 7) {
logger.error("Failed in propose.Retried {} times.", 7);
throw new IllegalStateException();
}
}如果去掉这个随机等待,在多核机器运行单元测试非常容易出现重试失败。
到这里,系统基本功能就完成了。我们的系统很简单,但是低并发的场景,也够用了。
我们只保证了容错,如果要保证容量和系统吞吐量,我们需要对数据进行切分(sharding),不同机器处理不同范围的数据, 数据范围的划分可以会随系统容量而不断变化,这意味着本身在A机器的数据,可能需要移动到B机器上,读者可以思考一下如何在数据切分变化时保证顺序一致性。
同时,我们还没有实现并发及事务,这两个功能在分布式下,也是非常有趣的话题。